Association rules in JavaScript

Initially, this technique was used to find associations between products, purchased by users in online stores. As can be seen, this technique has real business value for selecting and suggesting products that are relevant from the user’s perspective and have a high probability of purchase.
Association testing involves searching a set and determining such subsets that are related to each other, using the probabilities of a given element.
Among the applications of such algorithms, we can present the so-called basket analysis performed in stationary and online stores, which allows us to detect dependencies between purchased products and, for example, the time of their purchase (for example, during the holiday season certain products will be bought more often).
However, it can be noted that both negative rules are useful in business applications. Hard facts about how users buy products can change the outlook of business analysts.
Such rules can be used not only in product analysis, but also in medicine, biology or other sciences. Finding relationships between selected events can lead to many useful conclusions.
From the math side
Suppose we have a database containing a list of products purchased collectively by a customer. In such collection, we have information on whether a particular product was bought or not. Association algorithms usually ignore other data, such as the number of products purchased. Based on the data, we can assume that the probability of buying X if the customer bought Y and Z is 20%.
Often in the literature, the probability that two items will occur together in a subset (i.e., the customer will buy them both) is called support, i.e. the support for a set of Y and Z items is 40%.
So we can express this relationship, using the formula:
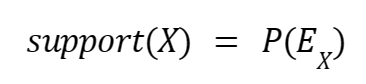
An association rule is one in which event X causes event Y to occur. We can write it as X ->Y. For example, according to our previous set, we can write the rule Y, Z -> X.. The rule itself does not really tell us much about its utility.
So it is important to introduce some measure that determines the strength of the relationship, the so-called confidence. This is a measure that determines the conditional probability that determines the co-occurrence of certain products.
We can declare confidence as the support of all elements of the rule divided by the support of the element to the right of the rule:
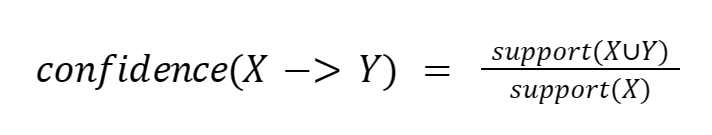
There are also other ways and measures to assess the relationship between elements, such as lift or collective strength.

Suppose we have an online store, containing dozens of products. Each user, can buy any number of products, which gives us a very large number of possible combinations that would have to be calculated when determining association rules. Therefore, in real cases, sophisticated algorithms are used to reduce the number of sets, by searching for the most probable ones.
Apriori algorithm
The Apriori algorithm is an algorithm that first restricts the subset search space by filtering out unique products based on the minimum level of support.
When a product has low support, we discard it in further analysis on the grounds that it has not been bought very often. Similarly, when a particular combination is bought infrequently, it makes no sense to check whether the same combination containing other items in addition has sufficient support.
This significantly limits the subsets lying in our area of interest. Note, however, that this way may lead to overlooking such combinations of elements that are relevant and occur together, but their subsets no longer do.
Example
- 1. Let’s create a new directory by following the commands:
mkdir assosiations
cd assosiations2. Then let’s prepare a new project by following the commands:
npm init
touch index.js3. Let’s also install the apriori library, which contains an implementation of the algorithm:
npm install apriori4. In order to test the performance of the algorithm, let’s prepare an example dataset, containing a list of products bought by one user in one transaction. Let’s use the dataset for this purpose, possible to download here:
5. The downloaded file is in csv format, so in order to load it into the program code, let’s install the needed library by running the following command:
npm i csvtojson6. Next, in the code, we can add the file loading. However, let’s select only the columns we will need, i.e. Member_number, Date and itemDescription.
const csv = require('csvtojson');
const jsonArray = await csv({
colParser: {
"Member_number": "number",
"Date": "string",
"itemDescription": "string",
"year": "omit",
"month": "omit",
"day": "omit",
"day_of_week": "omit",
},
}).fromFile("./Groceries data.csv");
7.The example object from the loaded array will view as follows:
{
Member_number: 2555,
Date: '2015-12-23',
itemDescription: 'whole milk'
}8. The next step is to group the products by users and dates. To do this, let’s use the Lodash library which we install with the command:
npm i lodash9. Next, let’s make a grouping, as follows:
let data = _.groupBy(jsonArray, ({ Member_number, Date }) => JSON.stringify({ Member_number, Date }));10. Under each common key, the data will be grouped into an array. An example array looks as follows:
'{"Member_number":3762,"Date":"2014-10-31"}': [
{
Member_number: 3762,
Date: '2014-10-31',
itemDescription: 'salt'
},
{ Member_number: 3762, Date: '2014-10-31', itemDescription: 'oil' }
]11. Then let’s map such data to an array of arrays of product names, since such a structure is necessary for the inputs of the apriori algorithm:
data = Object.values(data).map(v => v.map(w => w.itemDescription))12. Let’s now prepare a previously installed library with an implementation of the apriori algorithm:
const apriori = require('apriori');
const Apriori = new apriori.Algorithm(0.01, 0.05, false)
const results = Apriori.analyze(data)
console.log(results.associationRules)
13. The values of the parameters of the constructor of the Algorithm class express, in turn: minimum support, minimum confidence,and whether the algorithm should log individual results during its execution. Thus, the result of the above code will be:
[
a {
lhs: [ 'rolls/buns' ],
rhs: [ 'whole milk' ],
confidence: 0.12697448359659783
},
a {
lhs: [ 'whole milk' ],
rhs: [ 'rolls/buns' ],
confidence: 0.0884468895471858
},
a {
lhs: [ 'other vegetables' ],
rhs: [ 'rolls/buns' ],
confidence: 0.08648056923918994
},
a {
lhs: [ 'soda' ],
rhs: [ 'whole milk' ],
confidence: 0.11975223675154853
},
a {
lhs: [ 'yogurt' ],
rhs: [ 'whole milk' ],
confidence: 0.1299610894941634
}
]
This is a collection of rules that obtained the required certainty. In this case, for example, when a product called “soda” was purchased there was also a product called “whole milk” in the shopping cart along with it.

Summary
As you can see in the above example, the implementation of a simple algorithm for making recommendations in Javascript, is not particularly difficult or challenging. Just understanding how the Apriori algorithm works, is the key to other solutions, more efficient and using more sophisticated methods.
The Apriori algorithm is a method used in data mining to identify frequent sets of items in large data sets. The algorithm uses a brute-force approach in which frequent sets of items are first searched for, and then association rules are generated based on them. The association rules themselves identify relationships between items in the dataset. The article presents examples of association rules and discusses a technique for using them in data analysis.
Do you want to work on interesting projects together with a group of specialists from different fields? You could not have hit it better 🙂
Check out our current job openings under the Careers tab!
- Groceries dataset on Kaggle
- Burak Kanber, Hands-on Machine Learning with Javascript, Packt, 2019
- YenWee Lin, Data Mining: Market Basket Analysis with Apriori Algorithm.
Adam Gałęcki
Digital Marketing Specialist | I create content and run SEO campaigns on a daily basis.

