Reguły asocjacyjne w JavaScript
 Poniższy artykuł to jedna z części tworzonego na bieżąco kursu, który pomoże Ci opanować praktyczne umiejętności, które pozwolą Ci w pełni wykorzystać potencjał sztucznej inteligencji. Chcesz przejść do pozostałych lekcji?
Poniższy artykuł to jedna z części tworzonego na bieżąco kursu, który pomoże Ci opanować praktyczne umiejętności, które pozwolą Ci w pełni wykorzystać potencjał sztucznej inteligencji. Chcesz przejść do pozostałych lekcji?
Znajdziesz je tutaj: Praktyczne wykorzystanie AI

Początkowo odkrywanie asocjacji używane było do odnajdowania powiązań między produktami, kupowanymi przez użytkowników w sklepach internetowych. Jak można zauważyć, technika ta ma realną wartość biznesową, pozwalającą na dobieranie i proponowanie produktów istotnych z perspektywy użytkownika i posiadających wysokie prawdopodobieństwo zakupu.
Badanie asocjacji polega na przeszukiwaniu zbioru i wyznaczaniu takich podzbiorów, które są powiązane ze sobą, używając do tego prawdopodobieństw wystąpienia danego elementu.
Wśród zastosowań takich algorytmów, możemy przedstawić właśnie tzw. analizę koszykową dokonywaną w sklepach stacjonarnych i internetowych, która pozwala nam na wykrycie zależności między kupowanymi produktami, a np. czasem ich kupienia (przykładowo w okresie świątecznym pewne produkty będą kupowane częściej).
Można jednak zauważyć, że również reguły negatywne są przydatne w zastosowaniach biznesowych. Twarde fakty, dotyczące sposobu kupowania produktów przez użytkowników, potrafią zmienić spojrzenie analityków biznesowych.
Reguły takie mogą być stosowane nie tylko przy analizie produktów, ale również w medycynie, biologii czy w innych naukach ścisłych. Odnajdowanie związków między wybranymi zdarzeniami może prowadzić do wielu przydatnych wniosków.
Od strony matematycznej
Przyjmijmy, że posiadamy bazę danych, zawierającą listę produktów kupowanych wspólnie przez klienta. W zbiorze takim mamy informacje, czy dany produkt został kupiony, czy nie. Algorytmy asocjacji najczęściej pomija inne dane, takie jak ilość zakupionych produktów. Bazując na danych możemy przyjąć, że prawdopodobieństwo kupienia X w przypadku gdy klient kupił Y i Z wynosi 20%.
Często w literaturze prawdopodobieństwo, że dwa elementy wystąpią razem w jednym podzbiorze (czyli klient kupi je oba), nazywane jest wsparciem (ang. support), czyli wsparcie dla zbioru elementów Y i Z wynosi 40%.
Możemy więc wyrazić tę zależność, za pomocą wzoru:
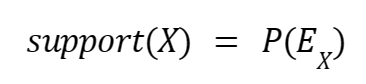
Reguła asocjacyjna to taka reguła, w której zdarzenie X powoduje wystąpienie zdarzenia Y. Możemy ją zapisać jako X -> Y. Przykładowo, zgodnie z naszym poprzednim zbiorem możemy zapisać regułę Y, Z -> X. Sama reguła nie mówi nam tak naprawdę wiele o jej użyteczności.
Ważne jest więc wprowadzenie pewnej miary, określającej siłę relacji, tzw. wiarygodności (ang. confidence). Jest to miara, która określa prawdopodobieństwo warunkowe, określające współwystępowanie pewnych produktów.
Wiarygodność możemy zadeklarować jako wsparcie wszystkich elementów reguły podzielone przez wsparcie elementu z prawej strony reguły:
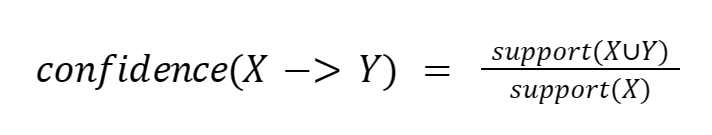

Przyjmijmy, że posiadamy sklep internetowy, zawierający kilkadziesiąt produktów. Każdy użytkownik, może kupić dowolną liczbę produktów, co daje nam bardzo dużą liczbę możliwych kombinacji, które należałoby obliczyć podczas wyznaczania reguł asocjacyjnych. Dlatego też, w realnych przypadkach stosuje się wyszukane algorytmy, umożliwiające ograniczenie ilości zbiorów, poprzez wyszukiwanie tych najbardziej prawdopodobnych.
Algorytm Apriori
Algorytm Apriori jest algorytmem, który najpierw ogranicza przestrzeń wyszukiwania podzbiorów poprzez odfiltrowanie unikalnych produktów na podstawie minimalnego poziomu wsparcia.
W przypadku, gdy dany produkt posiada małe wsparcie, to odrzucamy go w dalszej analizie, ze względu na to, że nie był on kupowany zbyt często. Podobnie gdy dana kombinacja jest kupowana rzadko, nie ma sensu sprawdzanie, czy ta sama kombinacja zawierająca dodatkowo inne elementy posiada wystarczające wsparcie.
Znacząco ogranicza nam to podzbiory leżące w obszarze naszego zainteresowania. Należy jednak pamiętać, że sposób ten może prowadzić do pominięcia takich kombinacji elementów, które są istotne i występują wspólnie, jednak ich podzbiory już nie.
Przykład
- Stwórzmy nowy katalog, wykonując polecenia:
mkdir assosiations
cd assosiations2. Następnie przygotujmy nowy projekt, wykonując polecenia:
npm init
touch index.js3. Zainstalujmy również bibliotekę apriori, zawierająca implementację algorytmu:
npm install apriori4. W celu zbadania działania algorytmu przygotujmy przykładowy zbiór danych, zawierający listę kupionych produktów przez jednego użytkownika w jednej transakcji. Wykorzystajmy w tym celu zbór danych, możliwego do pobrania poniżej:
5. Pobrany plik jest w formacie csv, więc aby wczytać go do kodu programu, zainstalujmy potrzebną bibliotekę, wykonując następujące polecenie:
npm i csvtojson6. Następnie w kodzie możemy dodać wczytanie pliku. Wybierzmy jednak tylko te kolumny, które będą nam potrzebne, tj. Member_number, Date oraz itemDescription.
const csv = require('csvtojson');
const jsonArray = await csv({
colParser: {
"Member_number": "number",
"Date": "string",
"itemDescription": "string",
"year": "omit",
"month": "omit",
"day": "omit",
"day_of_week": "omit",
},
}).fromFile("./Groceries data.csv");
7. Przykładowy obiekt z wczytanej tablicy będzie oglądał następująco:
{
Member_number: 2555,
Date: '2015-12-23',
itemDescription: 'whole milk'
}8. Następnym krokiem jest pogrupowanie produktów wg. użytkowników oraz dat. W tym celu użyjmy biblioteki Lodash, którą zainstalujemy poleceniem:
npm i lodash9. Następnie dokonajmy grupowania, w następujący sposób:
let data = _.groupBy(jsonArray, ({ Member_number, Date }) => JSON.stringify({ Member_number, Date }));10. Pod każdym wspólnym kluczem, dane zostaną zgrupowane w tablicy. Przykładowa tablica wygląda następująco:
'{"Member_number":3762,"Date":"2014-10-31"}': [
{
Member_number: 3762,
Date: '2014-10-31',
itemDescription: 'salt'
},
{ Member_number: 3762, Date: '2014-10-31', itemDescription: 'oil' }
]11. Następnie zmapujmy takie dane na tablicę tablic nazw produktów, gdyż taka struktura jest konieczna do wejścia algorytmu apriori:
data = Object.values(data).map(v => v.map(w => w.itemDescription))12. Przygotujmy teraz wcześniej zainstalowaną bibliotekę z implementacją algorytmu apriori:
const apriori = require('apriori');
const Apriori = new apriori.Algorithm(0.01, 0.05, false)
const results = Apriori.analyze(data)
console.log(results.associationRules)
13. Wartości parametrów konstruktora klasy Algorithm wyrażają kolejno: minimalne wsparcie (support), minimalną pewność (confidence) oraz informację czy algorytm ma logować poszczególne wyniki podczas jego trwania. Wynikiem powyższego kodu będzie więc:
[
a {
lhs: [ 'rolls/buns' ],
rhs: [ 'whole milk' ],
confidence: 0.12697448359659783
},
a {
lhs: [ 'whole milk' ],
rhs: [ 'rolls/buns' ],
confidence: 0.0884468895471858
},
a {
lhs: [ 'other vegetables' ],
rhs: [ 'rolls/buns' ],
confidence: 0.08648056923918994
},
a {
lhs: [ 'soda' ],
rhs: [ 'whole milk' ],
confidence: 0.11975223675154853
},
a {
lhs: [ 'yogurt' ],
rhs: [ 'whole milk' ],
confidence: 0.1299610894941634
}
]

Podsumowanie
Jak widać w powyższym przykładzie, implementacja prostego algorytmu służącego do tworzenia rekomendacji w języku Javascript, nie jest specjalnie trudna i wymagająca. Samo zrozumienie działania algorytmu Apriori, stanowi klucz do innych rozwiązań, bardziej wydajnych i stosujących bardziej wyszukane metody.
Algorytm Apriori to metoda wykorzystywana w eksploracji danych, pozwalająca na identyfikację częstych zbiorów przedmiotów w dużych zbiorach danych. Algorytm wykorzystuje podejście brute-force, w którym najpierw wyszukuje się częste zbiory przedmiotów, a następnie na ich podstawie generowane są reguły asocjacyjne. Same reguły asocjacyjne pozwalają na identyfikację zależności między przedmiotami w zbiorze danych. W artykule przedstawione zostały przykładowe reguły asocjacyjne oraz omówiona technika ich wykorzystania w analizie danych.
- Groceries dataset on Kaggle
- Burak Kanber, Uczenie maszynowe z językiem Javascript, Helion, 2019
- YenWee Lin, Data Mining: Market Basket Analysis with Apriori Algorithm.
Chcesz stworzyć projekt oparty na algorytmach uczenia maszynowego i sztucznej inteligencji? Szukasz doświadczonego zespołu specjalistów?
Sprawdź co mamy do zaoferowania!
Search
Baza wiedzy


Ostatnie komentarze
Warto sprawdzić


Wymieńmy się wiedzą
Chcesz pracować w zespole, którego członkowie dzielą się ze sobą swoim doświadczeniem i wiedza? Pracuj z nami!